Data Preprocessing and Metrics in Data Imbalance
1. 前言
数据不均衡是常见的真实场景,本文总结常用的减缓数据不均衡影响的数据处理方法以及评价指标。
数据处理:
- 欠采样(Undersampling)
- 随机欠采样
- Tomek Link采样
- NearMiss采样
- One-Sided Selection采样
- 过采样(Oversampleing)
- 随机过采样
- SMOTE采样
- 综合采样
- SMOTE + Tomek Link
2. 欠采样与过采样
对于欠采样,就是压缩数据多的类别,使得数据多的类别和数据少的类别的数据量相似;对于过采样,就是扩展数据少的类别,使得数据少的类别和数据多的类别的数据量相似。
其中,数据多的类别称为主要类(majority),数据少的类别成为少数类(minority)。
欠采样就是随机地减少采样主要类,过采样就是随机复制少数类。有的人会认为欠采样是不好的,因为它丢掉数据;过采样是更好,因为它复制了数据。但实际是两者不一定谁更好:
- 过采样(复制数据)也会有缺陷:复制的数据会使得变量的方差比实际更小;(缺点)
- 过采样也会有好处,它会复制误差数量,如果一个样本容易被分类错误,那么将它复制多份后,该样本的误差会对模型有更大影响,从而促使模型关注该样本;(优点)
- 欠采样(减少数据)会让样本的方差比实际方差更高。(缺点)
2.1 Tomek Link欠采样
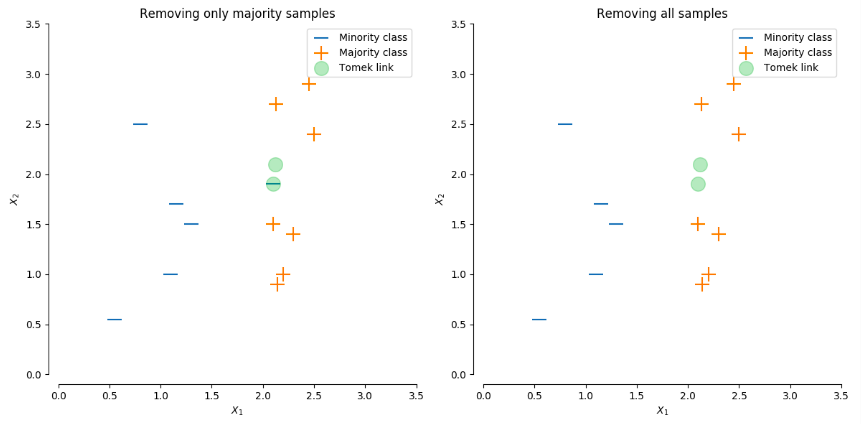
Tomek link采样的核心思想是,去除一些样本使得主要类和少数类之间存在明显边界。如下图所示,(左)图移除了少数类附近的多数类,(右)图则将少数类和多数类成对地移除。两种做法最终目的都是让类别之间产生明显的边界。如果少数类的数据量极少,那么不建议采用成对去除的方式;如果少数类的数据量还能够接受,那么两种方法都可以尝试。
2.2 NearMiss欠采样
NearMiss的思想与Tomek Link相似,核心思路都是拿走多数类使得多数类和少数类之间的距离大一些,关于“怎么拿”的问题衍生出三个版本。
“ NearMiss-1”选择多数类别样本,其与三个最接近的少数类别样本的平均距离最小。
“ NearMiss-2”选择多数类别样本,其与三个最远少数类别样本的平均距离最小。
“ NearMiss-3”为每个少数派样本抽取一定数量的最接近的多数派样本。
2.3 One-Sided Selection欠采样
该算法移除了噪声样本,边界样本和冗余样本。
- 噪声样本(Noise examples):离少数类很近的样本;
- 边界样本(Borderline examples):离边界很近的样本;
- 冗余样本(Redundant examples):周围有很多样本能够表示它。
2.4 SMOTE过采样
Synthetic Minority Oversampling Technique (SMOTE)算法弥补随机过采样的不足,算法步骤:
- 随机选择少数类的某个样本;
- 找到离它最近的\(k\)个样本(假设是\(k\)倍过采样);
- 将他们连线,在线上打点进行中值插值处理。
缺点:如果少数类的样本太分散,那么连线之间将可能存在大量多数类样本,那么在连线上采样将会破坏样本的原始分布,导致多数类和少数类重合。
2.5 综合采样
既然SMOTE有可能会出现破坏原始分布的情况,那么可以在SMOTE之后再进行欠采样,扩大多数类和少数类的边界,缓解多数类少数类重合的现象。
3. 不均衡分类中的指标
Accuracy是分类模型最常用的指标,它计算正确预测数与总预测数的比值。但是在不均衡的数据下,Accuracy存在缺陷,于是提出Precision(精确度),Recall(召回率)和F1-score等评估指标。
- Accuracy
- Precision
- Recall
- F1-score
4. 二分类问题
二分类中有以下指标:
True Positive(TP): 正样本预测为正(预测正确)
True Negative(TN):负样本预测为负(预测正确)
False Positive(FP):负样本预测为正(预测错误)
False Negative(FN):正样本预测为负(预测错误)
在二分类模型中:
\[Accuracy = \frac{TP + TN}{TP + TN + FP + FN}\] \[Precision = \frac{TP}{TP+FP}\] \[Recall = \frac{TP}{TP+FN}\] \[F1-score = \frac{2 \times Precision \times Recall}{Precision + Recall}\]不难理解,Precision表示模型预测为正样本的所有数据中,有多少是预测正确的;Recall表示在所有的正样本中,模型召回了多少(成功检测出了多少)。
4.1 更注重Recall的情况
当False Negative(FN)代价很高时,应着重考虑Recall。比如癌症的检测,如果把癌症患者(Positive)分类成健康(Negative),那会是非常严重的,可能导致耽误治疗。
4.2 更注重Precision的情况
当False Positive(FP)代价很高时,应着重考虑Precision。比如垃圾邮件检测,如果一封正常邮件(Negative)被分类为垃圾邮件(Positive),那么后果是严重的,用户可能错过重要的邮件。
5. 多分类问题
| Classes | Cat | Dog | Pig |
|---|---|---|---|
| Cat | FT | ||
| Dog | FT | ||
| Pig | FN | FN | TP |
我们需要针对每一类都计算Precision和Recall,所以每一类都有对应的一组Precision和Recall。那么应该如何综合评估模型的性能呢?
5.1 Macro-average方法
最简单的方法是把Precision,Recall各自求平均。
5.2 Weighted-average方法
考虑类别不平衡的情况,对类别赋予权重求平均。
5.3 Micro-average方法
该方法把每类的TP,FP,FN相加后,再根据二分类的公式计算。
6. AUC / ROC
Sensity:类别为1,模型预测为1的概率
\[sensity = \frac{number \ of \ true \ positives}{total \ number \ of \ sick \ individuals}\]Specificity:类别为0,模型预测为0的概率
\[specificity = \frac{number \ of \ true \ negatives}{total \ number \ of \ well \ individuals}\]以上两个指标不受data imbalance影响。
AUC:Area under curve 指曲线下的面积大小。
ROC:Receiver Operating Characteristic
ROC曲线是基于混淆矩阵得出的,纵轴为TP,横轴为FP。我们调整分类的threshold,TP值和FP值会变化,我们希望TP值很高的同时FP值很低,经过调整找到这样的threshold。曲线越接近左上方越好。这个指标也反映模型的泛化性。
PR-AUC: 纵轴为Precision,横轴为Recall。曲线越接近右上方越好。