Understanding Dropout
1. 过拟合
过拟合是很多机器学习算法的通病,它造成的原因有很多,从数据的角度看:
- 训练集与测试集分布不一致;
- 训练集与测试集分布一致,但是训练集中存在噪声;
- 训练集规模太小。
常见的解决方案有:
- 早停(Early stop);
- 对参数施加正则惩罚(L1 and L2 regularization)。
如果拥有无穷的计算能力,对模型正则化的最佳方式是:计算所有可能参数的模型预测结果的加权平均。即:
\[pred = \sum_i f(x | \theta_i) p(\theta_i | D_t)\]其中\(D_t\)表示训练集,\(\theta\)表示模型参数,\(x\)表示输入数据。但是对于深度学习而言,穷尽所有可能性是不现实的,需要其他方式来间接体现这个过程。
2. Dropout
Dropout是一种能够防止过拟合的技术,提供一种近似指数化组合多种不同神经网络结果的方法。
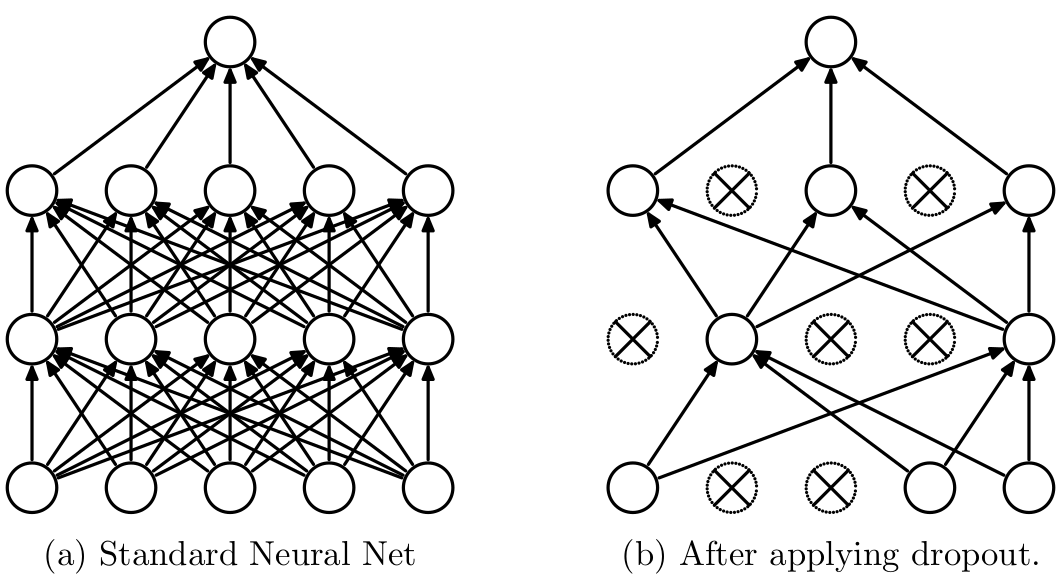
它的具体做法是在每一次训练网络时,随机地抑制掉某些神经元(输出为0),这种随机的做法通常是以概率\(p\)对每个神经元抑制。被抑制掉的神经元在该次梯度反传中不更新,没有被抑制的神经元则按照正常梯度下降法更新参数。
2.1 训练阶段
没有采用Dropout时:
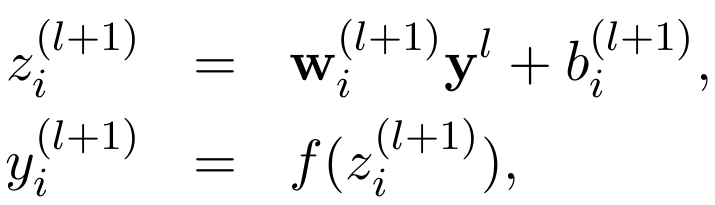
采用了Dropout后,为每个单元添加一个概率流程(伯努利分布):
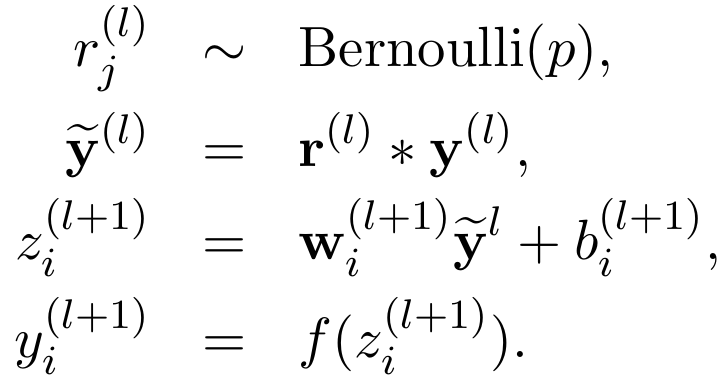
两者的流程图如下所示:
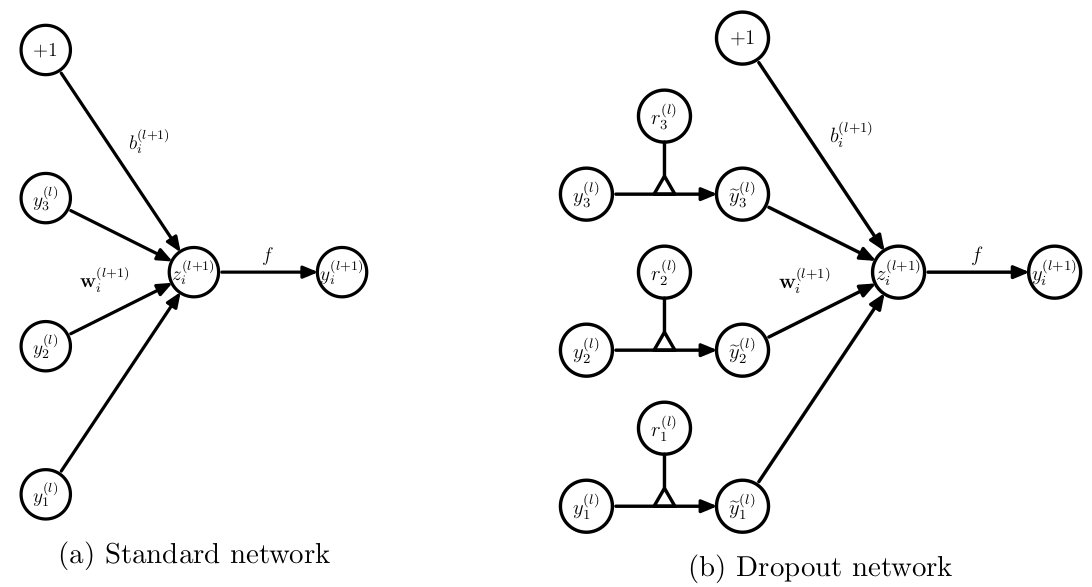
由于随机抑制一些神经元,那么输出到下一层的值的大小将会受到影响,所以需要进行一步缩放:对神经元输出值乘\(\frac{1}{1-p}\)。如果不进行缩放,那么要在测试阶段进行缩放。
2.2 测试阶段
如果训练过程没有进行缩放,那么测试时神经元的权重参数要乘\((1-p)\):
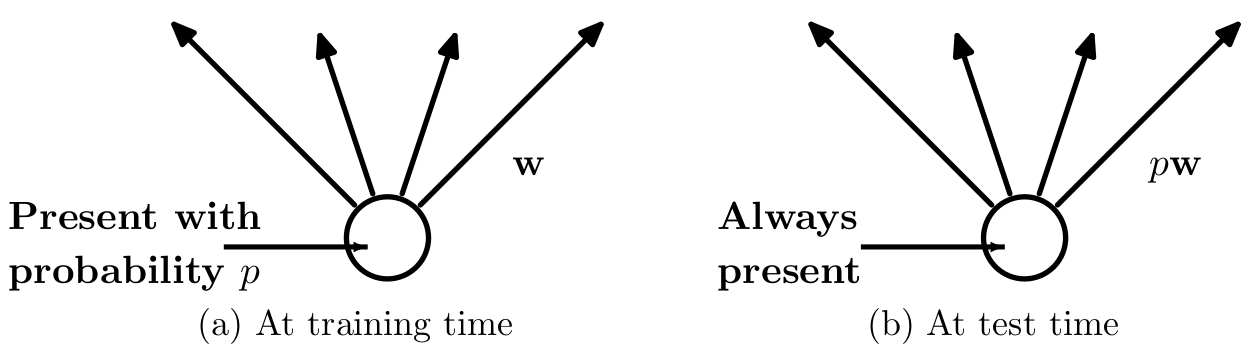
但是论文中写的是乘\(p\),这取决于代码实现时对\(p\)含义的理解:是以概率\(p\)保留神经元?还是以概率\(p\)抑制神经元。
对缩放的理解:
- 从输出分布的角度,由于训练时神经元是以一定概率抑制,所以为了保证测试时与训练时的神经元输出分布一致,需要rescale。
- 从Emsemble的角度,Dropout本质上是对指数个组合的网络进行集成,所以每个神经元应该以一定概率被集成,需要rescale。
3. 原理和动机
-
Emsemble:对神经网络采用Dropout会采样出大量“thinned”的小网络,拥有\(n\)个单元的网络可以采样出\(2^n\)个可能的小网络,训练过程中Dropout可以看成是训练\(2^n\)个权重共享的小网络,间接地达到集成的目的。
-
减少神经元之间复杂关系:普通的训练模式下部分神经元之间可能形成复杂的、隐含的关系;在Dropout下神经元之间不一定会同时激活,这迫使每个模型学习更加鲁棒的特征,迫使所有神经元之间能够互相地“合作”、学习特征。
-
生物进化学:有性生殖是父母各一半的基因加上基因突变,无性生殖是本体的基因加上基因突变。自然界中有性生殖是大多数高级生物的进化方式,有一种解释是:自然选择的标准可能是基因的混合能力而不是个体的适应能力。在神经网络中,每个隐藏单元在Dropout下必须要学会与其他随机的单元合作工作,这使得每个单元都更加强大,迫使他们依靠自己做正确的选择,而不是依靠其他单元纠正错误。
Reference
Dropout: A Simple Way to Prevent Neural Networks from Overfitting