Introduction to Semi / Weak / Self-supervised Learning
1. 背景
深度学习作为一个效果出色的工具,它需要大量的带标注数据进行训练。一般来说,带标签的训练数据越多、越准确则训练的模型效果越好。然而在实际应用中,场景有着多样的变化,例如数据不充足,或者数据量充足但缺乏标签,本文的出发点是后者,即:为数据打上标签的成本太大、时间太长。这种情况是非常多见的,例如医学图像中的标签需要专业医生来把关,然而医生是很忙的,不可能为计算机从业人员提供如此大量的标注信息;或者视频数据的标注,标注人员可能需要对每一帧图像打上标签,这将花费巨量的时间。因此,训练集中存在大量无标签数据是必然了,此时模型能否从大量的无标签数据中学习知识呢?于是就有人提出了半监督、弱监督、无监督学习等等训练方式。
1.1 概念
- Supervised learning(监督学习):顾名思义,数据集是全部标注,且标注的可信度是极高的,所以完全监督模型的训练。
- Semi-supervised learning(半监督学习):即数据集中只有少部分样本是有标注信息的,其余样本没有标注,且标注具有很高的可信度,但是没有全部标记完(可能是标注专家的数量不足,标注成本太大等原因)。此时的训练叫做半监督训练,即只有“一半”的数据是监督的,其他是没有监督的。
- Weak-supervised learning(弱监督学习):即数据集是部分或完全标注的,但是标注不具备很高的可信度(例如从朋友圈采集的图片+文字作为图文匹配的训练数据),这些数据如果要认真打上标签,则成本太大,可行性不高。此时的训练叫做弱监督训练,即监督性不强,标注有可能是不对的。
- Unsupervised learning(无监督学习):顾名思义,数据集完全没有标签信息。
- Self-supervised learning(自监督学习):个人理解它属于无监督学习的范畴。它可以在完全无标签的情况下使用,也可以在有少量标签的情况下用于提升模型能力。自监督学习通过某种方式产生“监督信息”,自定义任务进行自我训练,为下游任务做准备。
1.2 区分
我认为最好的区分方式是:1. 训练集标签的数量;2. 训练集标签的可信度。
| 标签数量是否充足 | 标签是否高可信 | 方法 |
|---|---|---|
| Y | Y | 监督学习 |
| - | Y | 半监督学习 |
| Y | - | 弱监督学习 |
| - | - | 无监督学习 |
但是这些方法的分类并非严格“非你即我”的形式,他们之中肯定有一些区域是相互重叠的。例如周志华老师的论文《A Brief Introduction to Weakly Supervised Learning》中将Weakly supervised learning分成三种类型:
- 不完全监督(incomplete supervision):只有一部分训练数据有标注信息,其余没有,类似于上述定义中的半监督学习;
- 不确切监督(inexact supervision):仅仅给出粗粒度的信息,例如分割任务中只给出bbox,对比学习中的“包”和“示例”;
- 不精确监督(inaccurate supervision):训练数据有标注信息,但是可能不准确,类似于上述定义中的弱监督学习。
根据周志华老师的定义:
- 半监督属于弱监督的一种;
- 如果人为对强监督信息进行干预,削弱监督信息,这也是一种弱监督。

总之,没有完美的区分方式,最重要的是理解!!!为了简便,后续内容都是根据表格中的区分方式进行阐述。
2. 半监督 / 不完全监督学习
场景:假设有大量的医学图像数据,可是医生没太多时间打标注,打了几十张就撤了,忙于其他重要工作。
与其说半监督学习是一种学习方式,不如说它是一种解决方法。此处的半监督可以理解为:不完全监督(incomplete supervision)。
2.1 常规半监督
既然只有少量的样本带有标签,那么只能将计就计,使用少量的样本先训练一个模型。使用训练的模型去为没有标签的样本打上伪标签,取一部分出来加入到训练数据中,进行迭代训练:

这是一个最直观、最简单的方式来为无标签数据打上标签,并使其参与到训练中,尽可能地挖掘无标签数据的信息。
还有一种类似方式,使用强大的pre-trained模型(ImageNet预训练)抽取出所有训练样本的特征,利用聚类的思想,为有标签样本附近的无标签样本打标签:
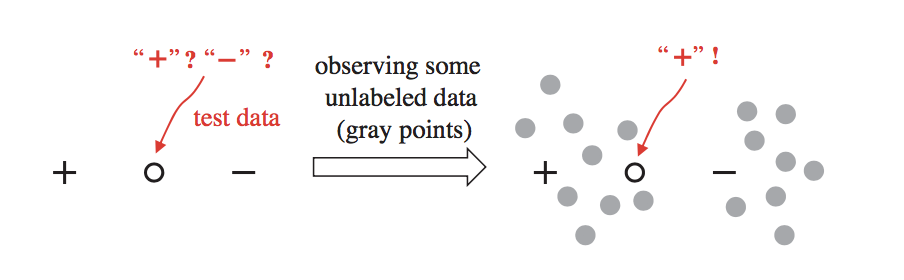
这种方式也是既“便宜”又简单,很容易就能够为无标签的数据打上标签并参与训练。
2.2 主动学习(Active Learning)
主动学习的的思路:通过一定的方法获取那些比较“难”的样本数据,把这些数据送给专家进行标注、审核,再将标注完成的数据拿回来训练。这种方式能够有效减少专家标注的时间,进而减少成本,因为送给专家标注的样本都是高质量的、重要的样本,对模型训练非常有帮助。
在主动学习领域,在进行方法对比时,肯定不会真的去向专家要标签,而是把原本有标签的数据隐藏到一个数据库中,训练时可以去数据库访问真实标签。方法的对比则是比较哪种方法能够在尽可能少地访问数据库的情况下,效果最好。
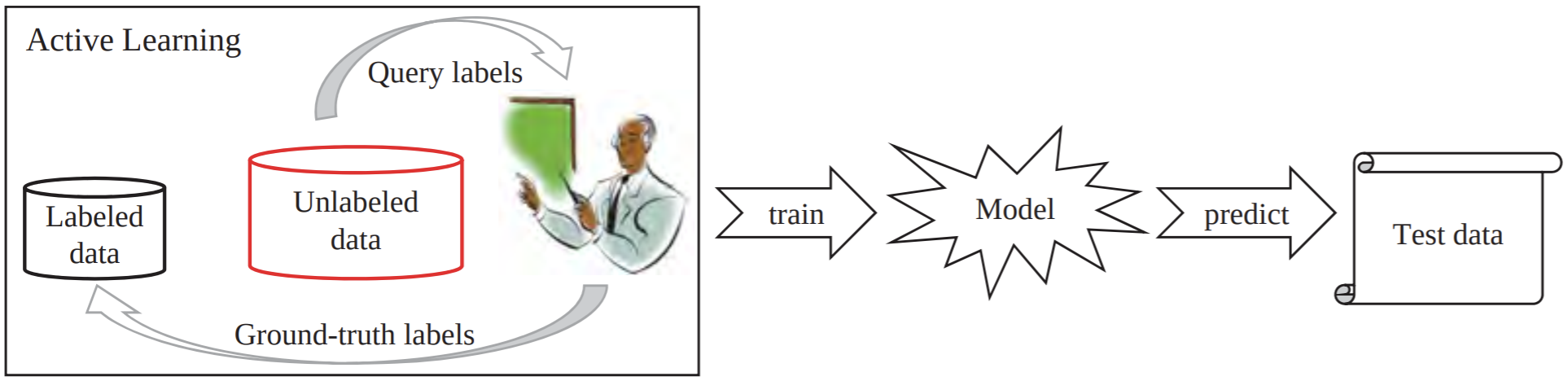
一般来说,有几种直观的选择“难”样本的思路:
- Least confident:选择分类器预测在Softmax后比较不确定的一些样本;
- Margin sampling:选择那些特征点在边缘的样本;
- … …
3. 弱监督 / 不确切监督学习
这个领域有点大,目前有不少研究,以后再作为专题展开。
4. 弱监督 / 不精确监督学习
场景:既然医生没时间给每一张医学图像样本标注,那就去找医学院的硕士生标注吧,给他们一点小钱作为奖励,可是这样一来标记的可信度就得不到保证了。
这种情况下的弱监督学习,我认为本质上是:如何使用带噪声的训练集进行模型训练。此处的弱监督理解为:不精确监督(inaccurate supervision)。
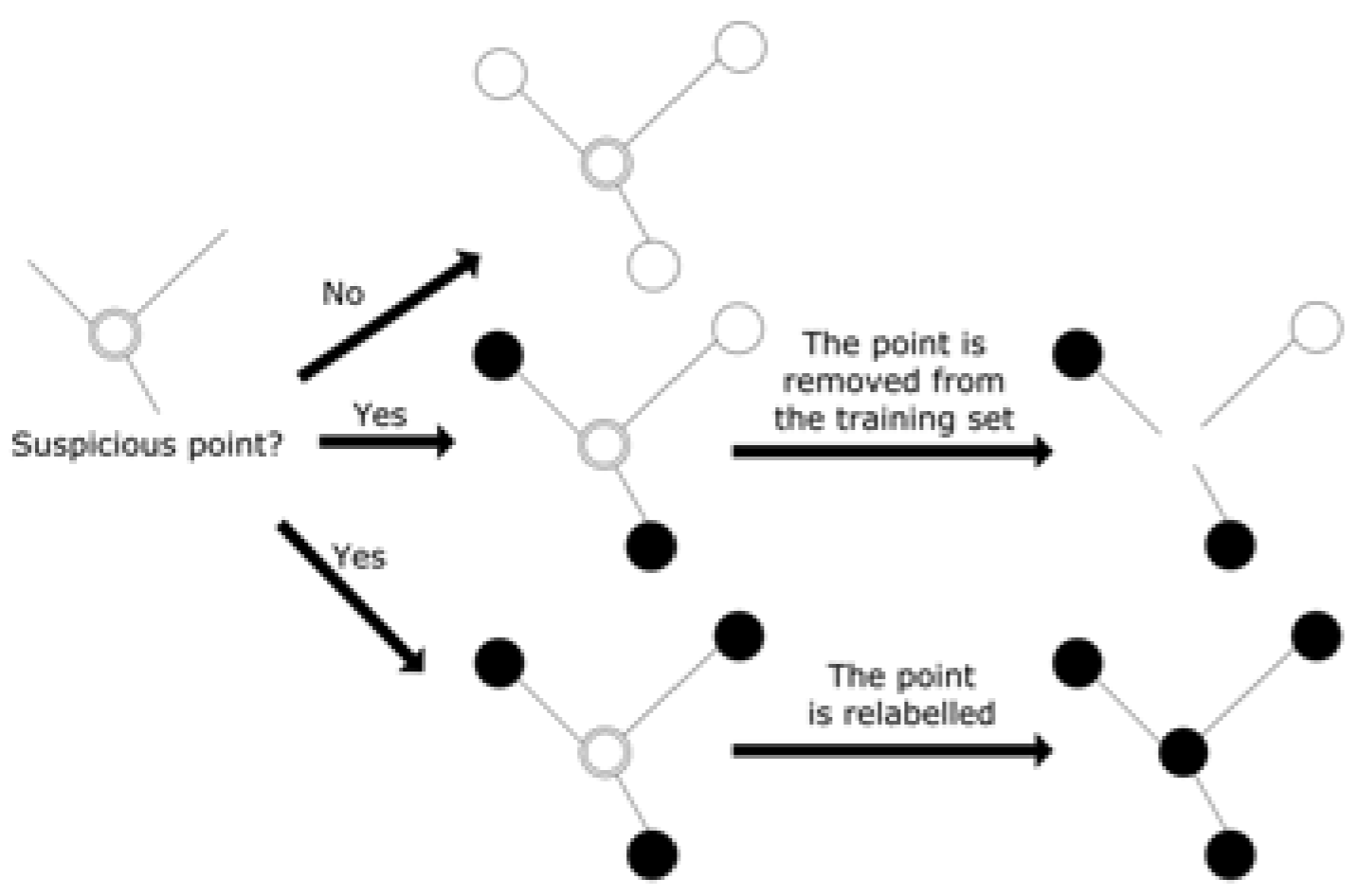
4.1 数据修正(Data Editing)
此处展示一个最直观、最简单的做法:数据修正。既然训练集中存在一些噪声,那么能否提前发现它们,去除或修正label。该方法构建一个无向图,每一个节点代表一个训练样本,每一条边代表两个样本距离比较近,如果一个节点连接出去的若干条边到达的节点,它们的标注一致性不高,那么该节点去除或修改标注:
5. 无监督 / 自监督学习
自监督学习作为无监督学习中的代表,在NLP / CV等领域都有广泛的应用。虽然自监督学习是在无监督学习的范畴内,但不代表自监督的方式不能应用到其他学习方式中,即使是带标签的训练集,配合上自监督的训练可能使得模型效果更好。
5.1 为什么使用自监督
- 第一章节提到的,数据集没有标签信息;
- 学习更好的知识、特征表示,为下游任务准备;
- 现实中的一些场景下,数据是无休止地到来的(视频、文字);
- 受到人类学习的启发[Yann LeCun’s talk]。
5.2 代理任务
在监督学习下,模型对特征的描述程度完全依赖于大量的数据和标签,无监督的情况下如何学习对特征的描述呢?自监督中的代理任务(pretext task)就是为了解决这个问题。没有标签就自己产生“标签”,然后对自己产生的“标签”作为监督信息定义任务来学习(自己监督自己),最终目的是学习更好的特征表示(representation learning),此处可以理解为获得一个良好的预训练的模型,为下游任务做准备,或者使用非参数的方法进行其他任务(KNN、聚类)。
关于如何理解产生“标签”并自我监督训练,举个著名的例子:BERT。众所周知,BERT使用了英语维基百科和其他语料进行预训练,它的预训练任务有两个:
- 在一句话中mask掉几个单词然后对mask掉的单词进行预测(masked language model);
- 判断两句话是否为上下文关系(next sentence prediction)。
维基百科的语料本身是没有标签的,也不可能让人去对这些语料进行标注,而模型在这两个自己定义的任务下预训练后,再放到其他下游任务中fine-tune就达到SOTA了,这就是自监督的强大实力。一般来说,这个自己定义的任务叫做代理任务(pretext task)。
5.3 CV中常用的代理任务
5.3.1 Distortion
-
剧烈的数据增强(Dosovitskiy et al., 2014)

这个方法非常直接,给图片加上较为剧烈的变化,让网络模型仍然认为他们是同一种类别。
-
旋转(Gidaris et al., 2018 )
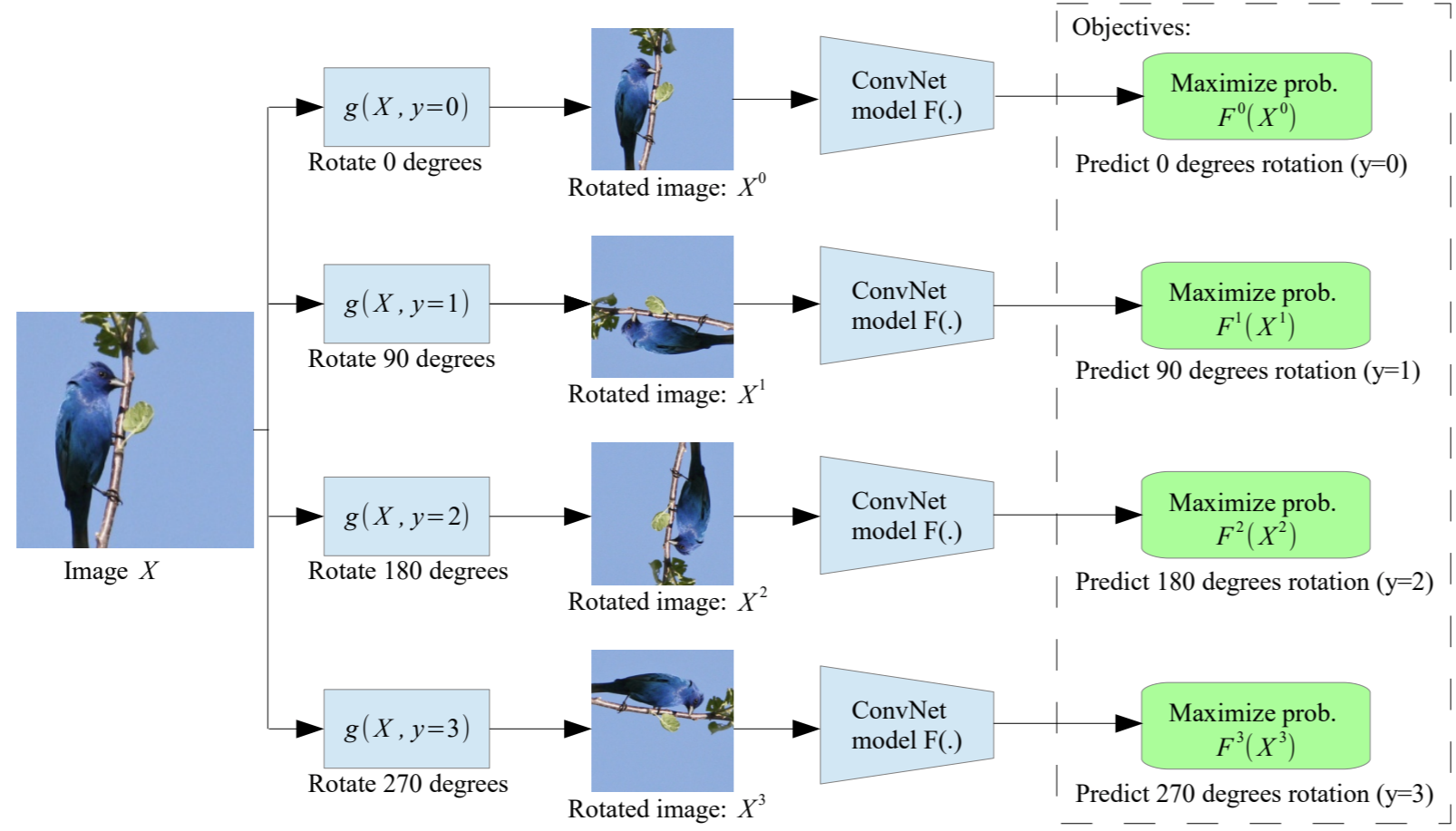
把图片进行一个或多个90度旋转,让旋转的角度作为标签信息监督模型训练。
5.3.2 Relative position
-
判断相对位置(Doersch et al., 2015)
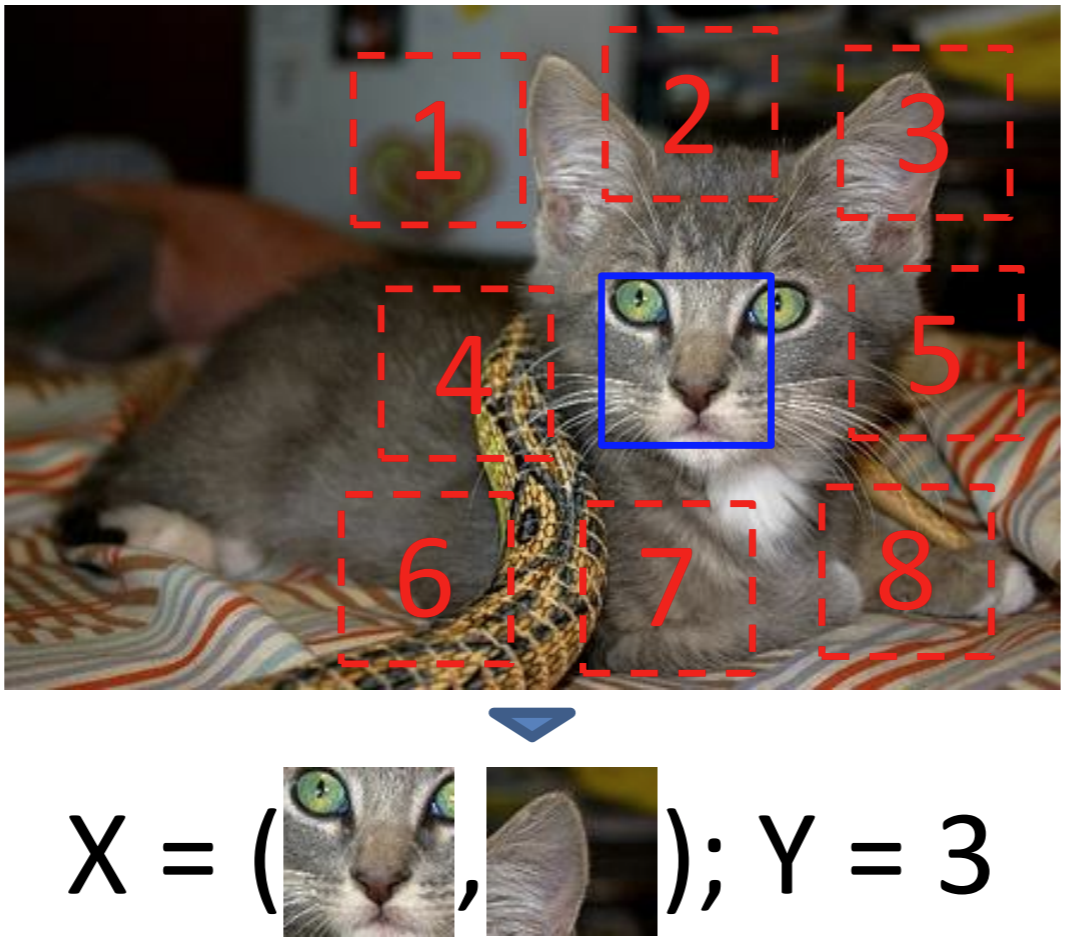
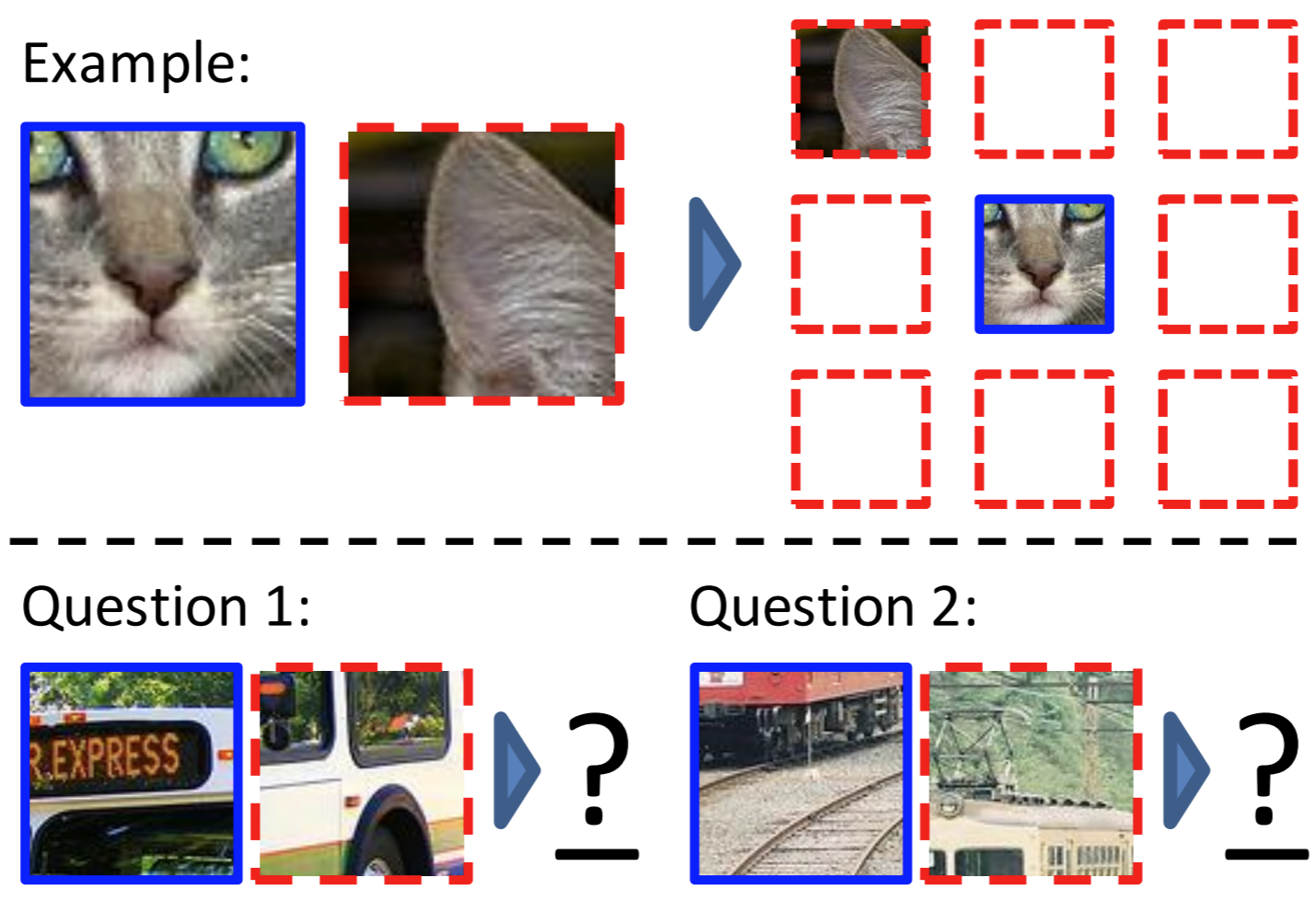
自定义的任务是判断两张图片的相对位置。随机地在图片一块划分为9个区域,以中心的区域为基准,其余8个区域的相对位置标记为1~8。给出中心的区域,判断其余区域分别是哪个位置的内容(左上角or右边or右下角…)。
-

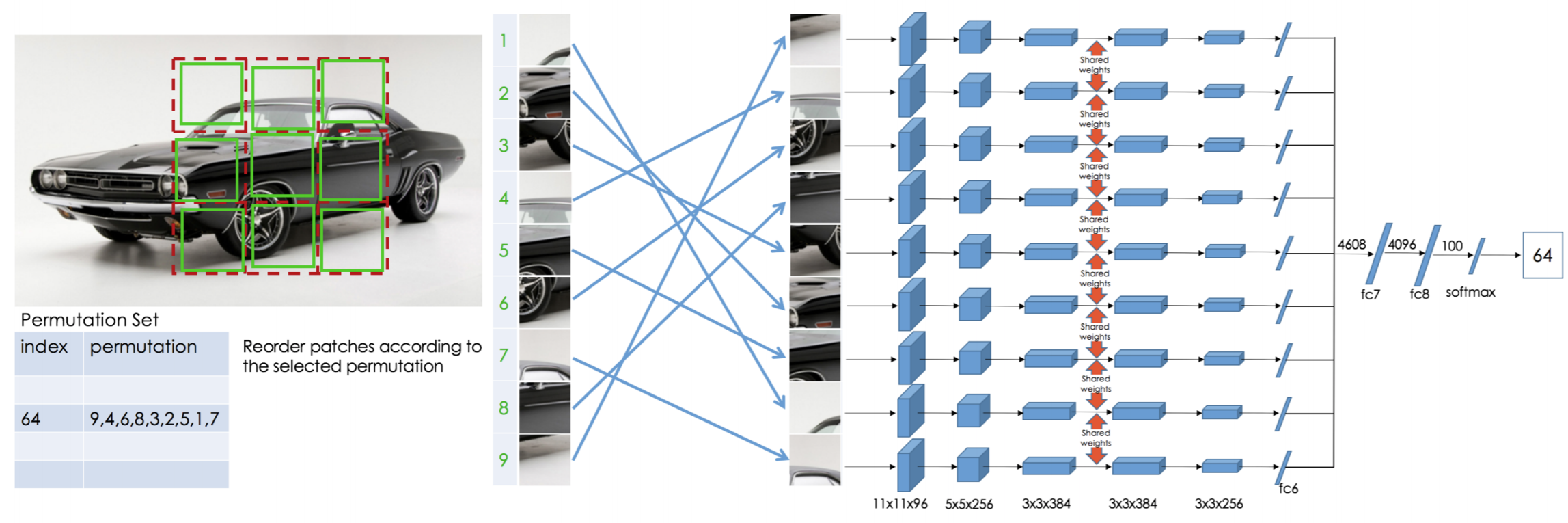
人具备还原拼图的能力,那么能否利用这一点进行自监督学习呢?为了简化任务,作者预先将图片块打乱,并为打乱的顺序赋予index,构建Permutation set,网络由许多并行的卷积模块构成,分别将9个区域送入9个并行网络,最终模型预测index的值。构建的Permutation set有多大,决定了最终进行几分类。
5.3.3 Colorization
-
颜色恢复(Zhang et al., 2016)

将RGB图像转变为灰度图构成一对样本,使用作者定义的衡量RGB恢复程度的损失函数进行自监督训练。
5.3.4 Generative modeling
-
AutoEncoders(Pathak et al., 2016)
各式各样的AE其实本质上都是一种自监督的学习方法,因为AE的训练没有使用人为标注的label。
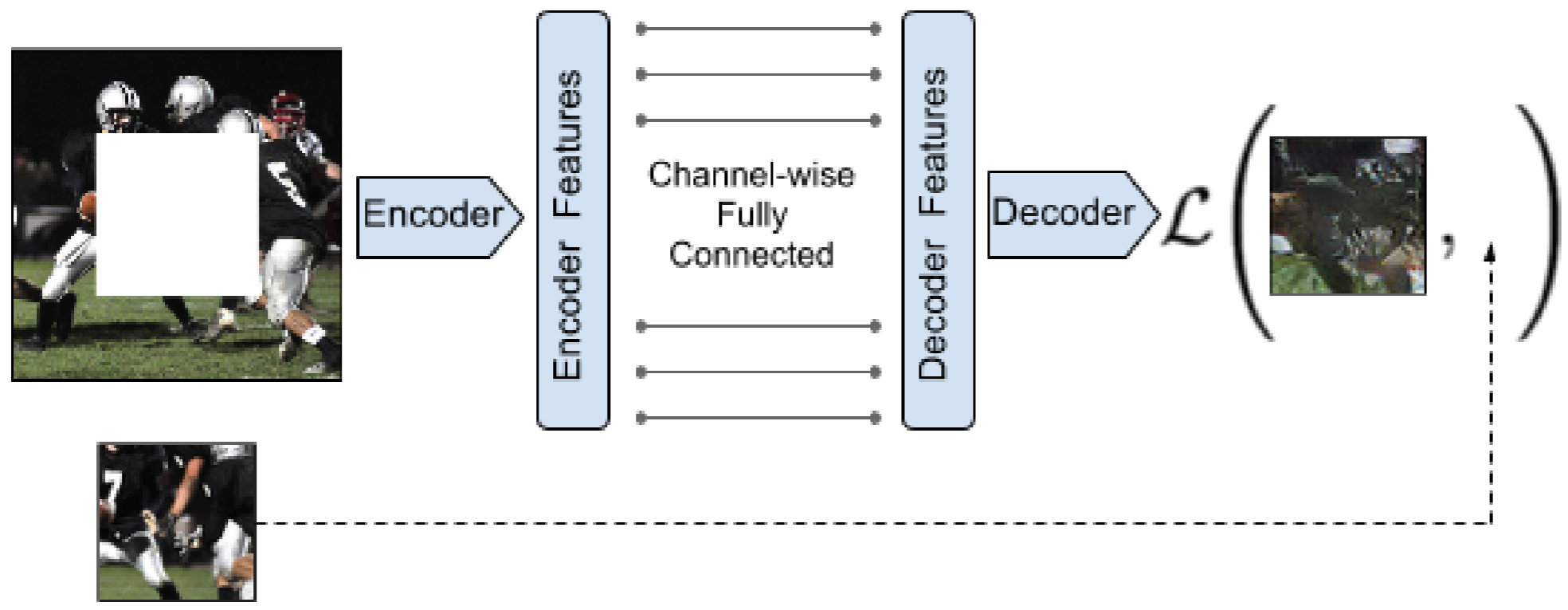
该方法尝试将原图抹去一部分,使用AE来恢复出原图。
-
GAN
如果AE算自监督学习方法的话,那么各式各样的GAN应该也都属于自监督的方法了。不过这一点仁者见仁,智者见智,大部分的自监督资料中没有提到GAN。
5.4 其余应用场景
- Video
- Robot
- Using time
- Using audio
5.5 小结
使用自监督方法一般包括两个步骤:
- 选择一个合适的代理任务(pretext task)进行训练;
- 在下游任务中微调。
代理任务即是上述提到的在无标签数据集上自定义“标签”和“任务”进行自训练,目的是让网络模型从数据集中提取丰富的信息,该代理任务的好坏很大程度上决定了下游任务的效果。
参考资料
CMU_semi_supervised_learning
Weak_supervision
Deepmind_slides_self_supervised_learning
Self_supervised_learning_and_computer_vision
Self_supervised_representation_learning
弱监督学习_综述_zhihu
浅谈弱监督学习_zhihu
Weakly_supervised_learning: Introduction_and_best_practices
A_brief_introduction_to_weakly_supervised_learning