A Brief Introduction to the Storage System Design of Hologres
0. 前言
本文是对发表在VLDB的论文《Alibaba Hologres: A Cloud-Native Servicefor Hybrid Serving/Analytical Processing》进行的简单解读,主要介绍其存储引擎部分。
1. 背景
1.1 概念的提出
- Serving场景是指线上服务,产生的数据一般会导入OLAP系统进行AP类型分析;
- OLAP系统能够帮助决策者从大数据中获取宝贵信息,从而帮助改进Serving场景的模型;
- 把这两套系统合在一起就成了HSAP(Hybrid Serving and Analytical Processing)系统。
1.2 以具体场景为例
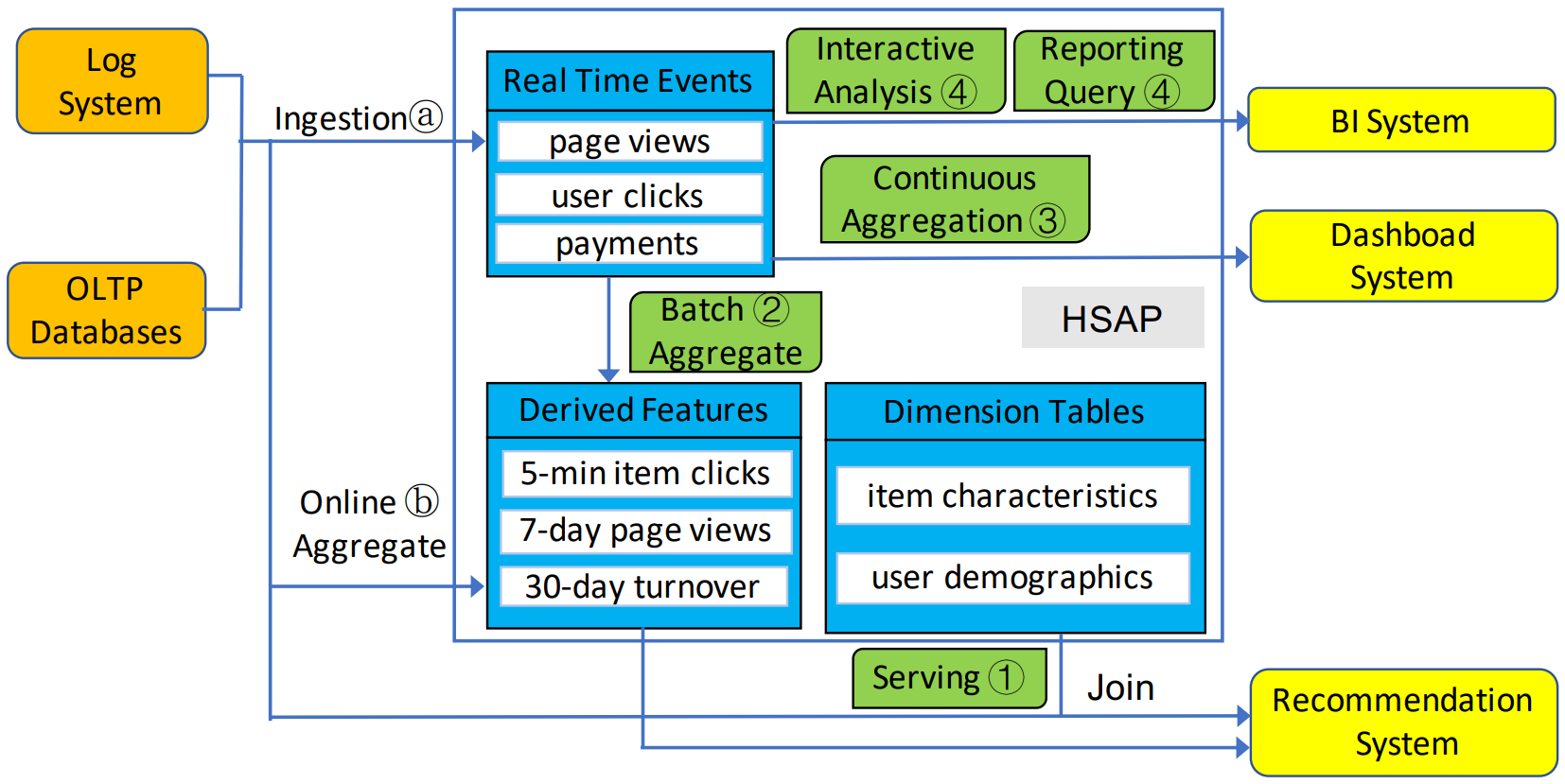
- 论文以推荐系统为例,上图中(a)流程为用户的简单行为(如点击、页面停留等,即Log System)会产生大量的实时数据入库;与此同时,用户的交易行为(如购买、退货等,即OLTP)也产生数据入库。
- 图中的(1)流程表示这些数据会与维表进行Join,得到的结果作为推荐系统的输入;图中的(2)和(b)流程表示用户产生的数据需要进行一定尺度的聚合。
- 流程(3)和(4)表示后台进行的AP类分析,对实时数据执行计算量较重的分析型SQL得到报表或大盘。
- 当前主流的架构中,Hive能处理过程(2),Cassandra能处理过程(1),Druid能处理过程(3),Impala/Greenplum能处理过程(4),而将他们整合在一起就是Hologres的目标。
1.3 面临的挑战
- 多样的Query类型,Serving场景一般为并发数较高的点查,报表或大盘一般为计算量较重的分析。
- 读写混合进行,要求写入即可查。
- 由于需要服务Serving场景,因此需要应对突发的高QPS场景,如双十一。
1.4 提出解决方案
- 存储设计:
- 计算/存储分离;
- 读/写分离;
- Data model:提出Table Group和Shard的概念。
- 调度框架设计:
- Execution Context:一种轻量级的User-space线程,能够大幅减小Context switch的开销。
2. 基本结构
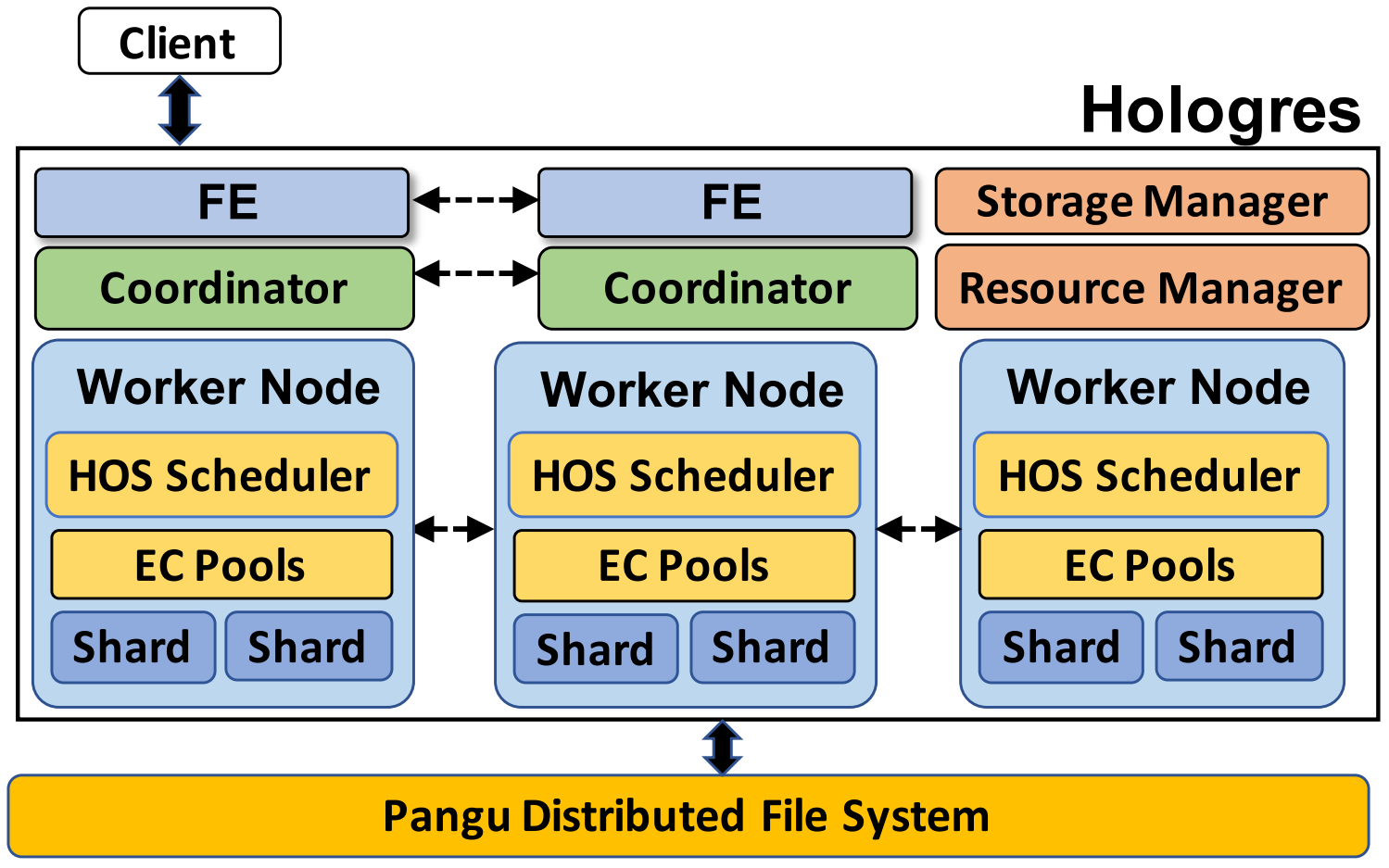
先自上而下地了解Holo的基本结构:
- Front-End(FE)与Client建立连接并接收SQL,FE中的Optimizer产生执行Plan发送给Coordinator;
- Coordinator将Plan的任务下发给Worker Node(理解为逻辑机器,带有CPU和Memory);
- Worker Node中运行Holo的调度器(HOS),调度EC Pool中的Execution Context(EC);
- 数据的读写走不同的链路在Shard上进行读写;
- Shard的数据落盘到底层的Pangu或开源HDFS上。
3. 存储设计
3.1 Table Group & Shard
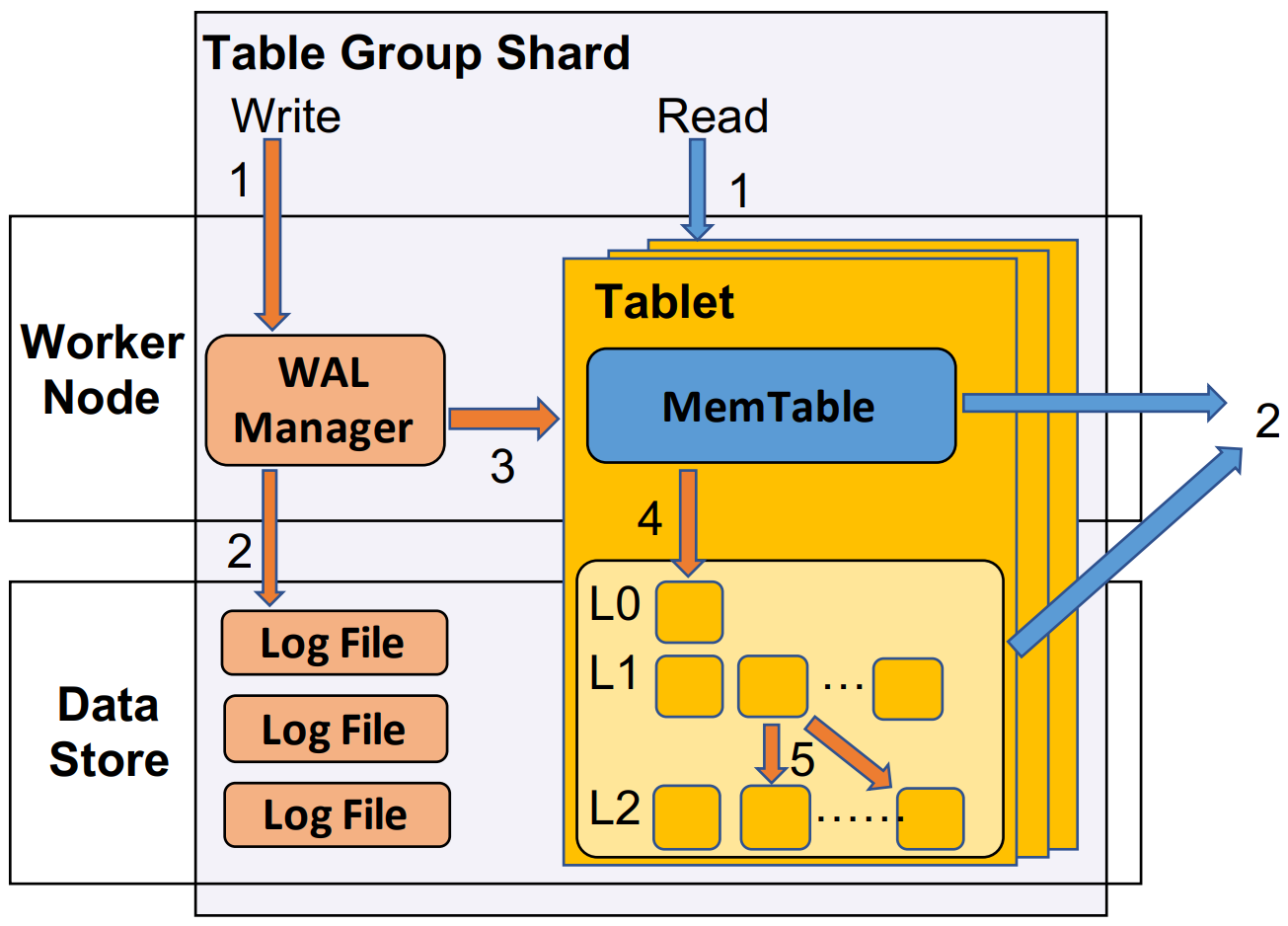
- Holo提出Table Group(TG)和Table Group Shards(TGSs)的概念。一个TG包含多个Table,一个TG对应多个Shard(一个Shard只能在一个TG)。一个TG中的Table会根据各自的Clustering key(一种索引,详见官方文档)将数据拆分到对应的Shard上,因此一个Shard会包含对应TG中所有Table的部分数据。
- Shard是Holo从宏观上管理数据的基本单位,一个Shard由多个Tablet(下面介绍)和一个WAL Manager组成。
- TGSs中的Writes的简化步骤:
- 收到请求后,WAL Manager会对这一条commit打上Log Sequence Number(LSN);
- 将commit写到Log file并落盘;
- 写请求在Tablet中的MemTable中执行;
- 当MemTable满后再Flush到盘上。
- TGSs中的Reads:
- Holo对读写进行了多版本管理,读一致性的保证是read-your-writes,即对于一个Clint而言,写入即可读;
- 每一个Read请求都会带\(LSN_{read}\),时间戳小于\(LSN_{read}\)的数据读出来,反之则过滤;
- TGSs对自己的每一个Tablet维护一个\(LSN_{ref}\),表示当前数据的最早版本,LSN小于\(LSN_{ref}\)表示写入的数据都被Merged了,而LSN大于\(LSN_{ref}\)的数据仍保留全量。
- TGSs的管理:
- 借助多版本管理,上述Reads和Writes实现解耦,明确了一致性的定义;
- TGSs这个概念是挂在Worker Node上的,当机器的负载较重时,机器上TGSs的读写会变慢,因此Holo支持TGSs的迁移;Worker Node上的资源从逻辑上划分成Slot,这些Slot是用来放TGSs的,借此机制实现资源管理调度;
- 如果Shard挂掉,Storage Manager会发送请求寻找一个可用的Slot,并广播给所有Coordinator告知Shard挂掉的信息,Coordinator会暂时停止需要访问正在Failover的Shard的请求;当Shard恢复后会根据WAL logs重现MemTable,最后再由Storage Manager广播给所有Coordinator该Shard恢复的消息。
3.1 Tablet
- Shard存储数据的形式为Tablet,它是由基本数据(文中称为Base data)和相关的索引(文中称为Indexes)组成。
- Tablet是以LSM-tree的形式管理的,它由Worker Node内存中的数据(MemTable)和落盘文件数据组成(LSM-tree存储结构的基本形式)。
5. Tablet
Tablet有两种类型:Row tablet和Column tablet,分别用于行存和列存。
5.1 Row Tablet
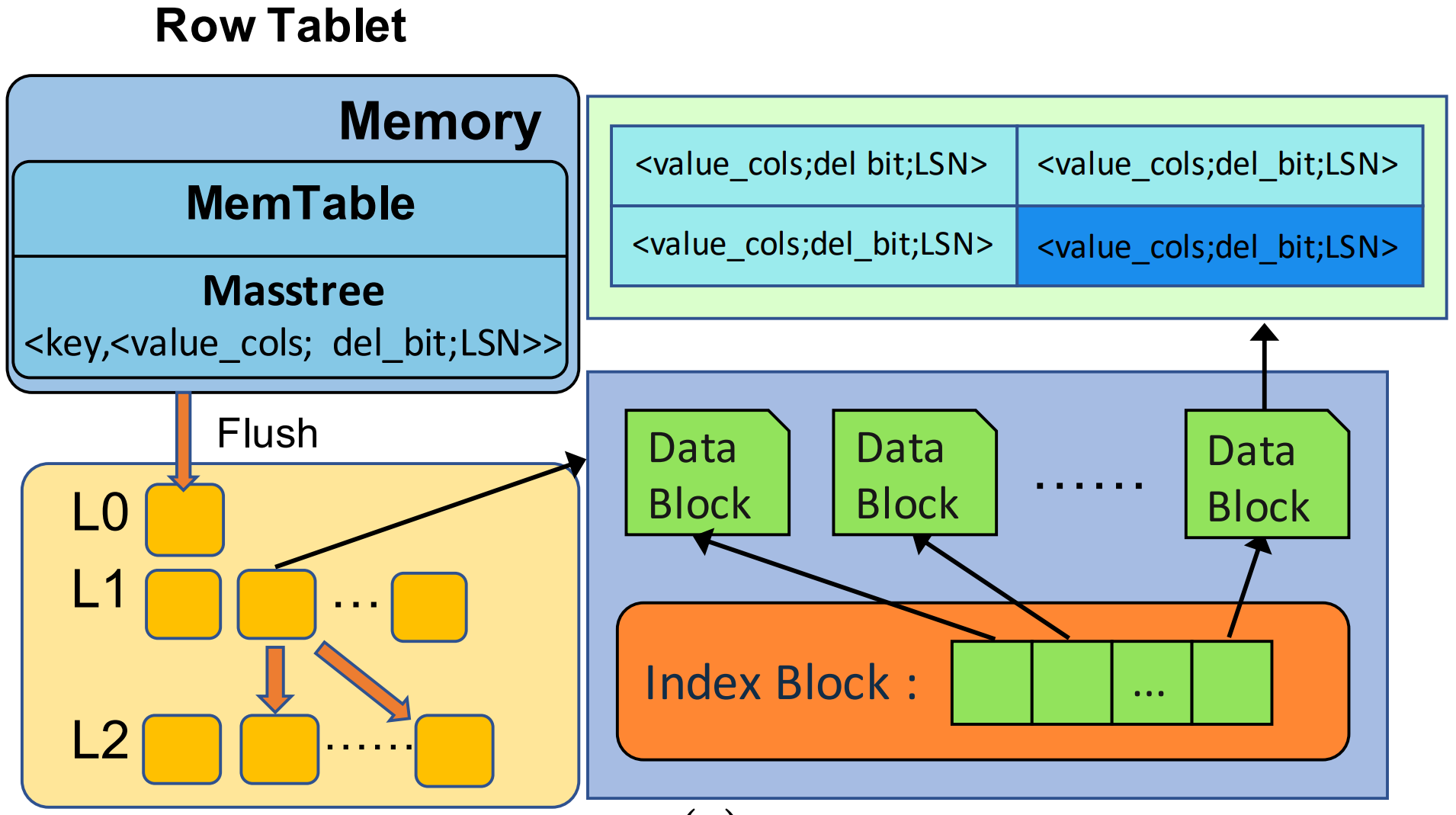
- MemTable的管理与Masstree类似,Tablet和Shard file里的Record都根据key排好序,且存储的形式为<key, <value_cols; del_bit; LSN>>,顾名思义:key表示主键,value_cols表示除了主键外的其他列,del_bit表示该记录是否删除,LSN则是序列数。根据LSM-tree的逻辑,在MemTable或Shard file中是可能存在多条LSN不一样但key一样的Record。
- Shard file是Block-wise的结构,它包括两种类型:Data block和Index block,分别对应数据和索引。
- 如上图所示,Data block内的数据排好序,Index block用于加速查询,它表示为<key, block_offset>,即Data block开头的key以及该Shard file的偏移量。
- Reads:
- 读取操作的请求包括:key和\(LSN_{read}\),在MemTable和Shard file中并行扫描Record,符合key满足且\(LSN_{read}\)也满足的记录会被筛选出来,称为candidate,同一个key取最大的LSN对应的Record作为最终结果(因为每条记录都是最新的值,因此取最大符合条件的LSN就是结果),如果发现del_bit为1,则过滤掉这条Record。
- Writes:
- 写入操作的请求包括:key、column values和\(LSN_{write}\),顾名思义:column values表示除了主键外的其他列的值。
5.2 Column Tablet
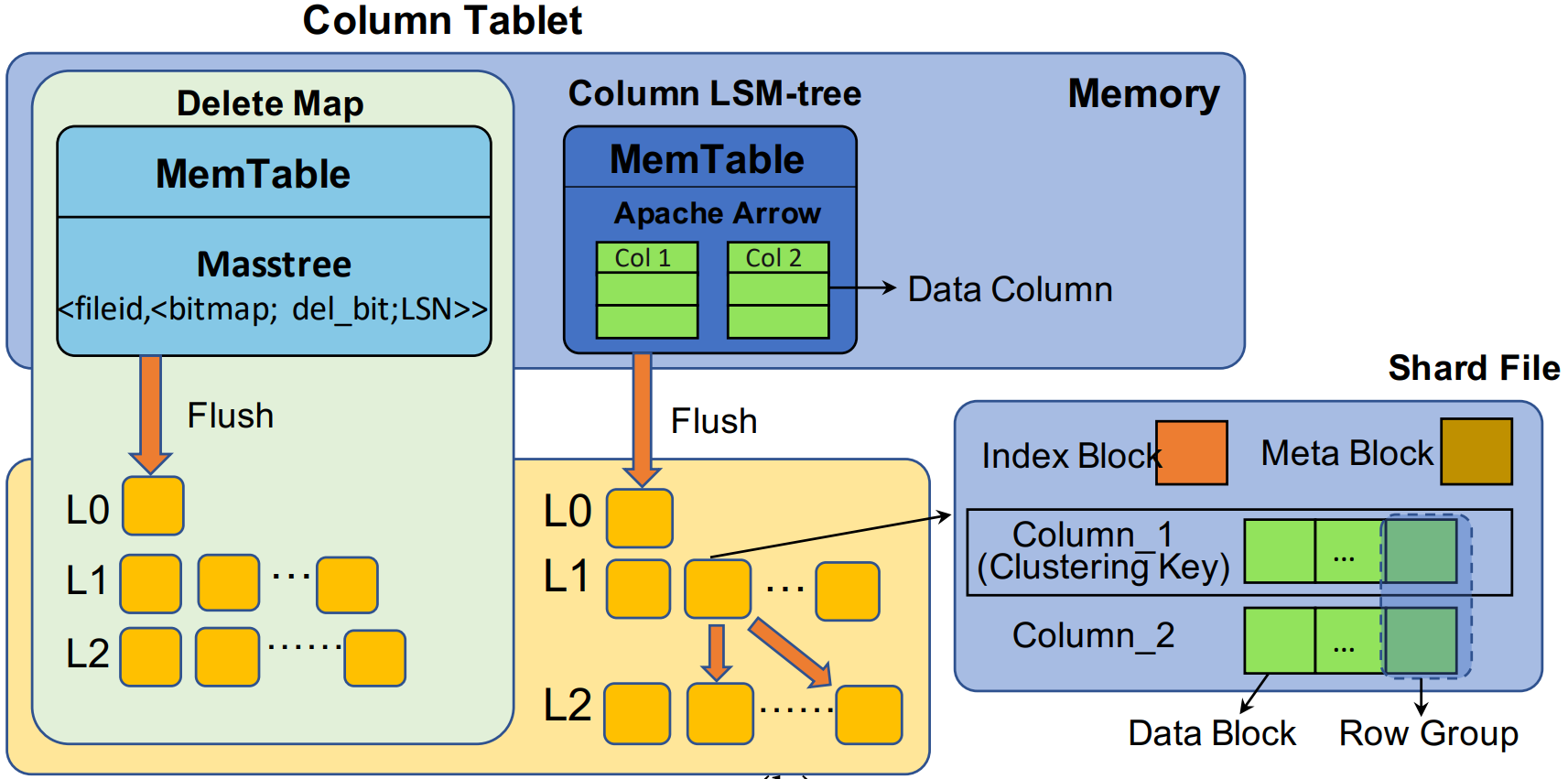
- Column tablet包括两部分:Column LSM-tree和Delete map。
- 在MemTable中数据是以Apache Arrow的格式存储,存储的形式为<value_cols, LSN>,概念与Row tablet中的定义一致。
- 在Shard file中,数据是以ORC的形式存储的,简单罗列几个重要的性质:
- 数据根据key排好序(与Row tablet中一致);
- 逻辑上划分Row group,一个Data block存放多行(为一个Row group)的某一列数据,多个Data block合在一起形成一个Row group,表示多行的所有列数据。
- Index block的设计与Row tablet中的一致,都是为了加速查询。
- Meta block同样为了加速查询设计,里面存储一些元信息(统计信息、offset等)。
- Delete map本身是一个Row tablet,其中key为Shard file的ID(把MemTable也看作是特殊的Shard file)。如图所示,它有自己的MemTable和Shard file。
- Delete map利用Bitmap记录被删除的Record,它的字段为<fileid, <bitmap; del_bit; LSN>>,fileid表示Shard file的ID,bitmap是针对Record的索引。
- 由此可以看出,Column tablet没有对每一条记录都写一个del_bit,而是使用Delete map来批量记录Record的删除情况,利用Bitmap的交操作加速过滤。
- Reads:
- 读取操作的请求包括:Target columns和\(LSN_{read}\),在MemTable和Shard file中并行扫描记录,扫描时会进行LSN的比较,此时会出现三种情况:
- Shard file的最小LSN大于\(LSN_{read}\),该Shard file会被跳过;
- Shard file的最大LSN小于等于\(LSN_{read}\),该Shard file所有Record都被读取;
- 其余情况下,该Shard file的部分Record被读取。
- 第三种情况的做法是:首先扫描Shard file的LSN,过滤出满足版本要求的Record并生成Bitmap,称为LSN bitmap;接着扫描Delete map得到没有被删除的Record,称为Delete bitmap,将两者进行交操作过滤出最终的candidate。
- 读取操作的请求包括:Target columns和\(LSN_{read}\),在MemTable和Shard file中并行扫描记录,扫描时会进行LSN的比较,此时会出现三种情况:
- Writes:
- 写入操作的请求包括:key、column values和\(LSN_{write}\)。
- 如果是删除操作则快速找到Record对应的Shard file和行号,接着Insert到Delete map。
- Update操作相当于先Delete再Insert。
5.3 Compaction
可以注意到,Flush落盘后底下还有\(L_0, L_1, L_2\)等字样,这就引出Compaction的概念,它的形式与RocksDB的Compaction类似。
- 落盘的数据分为很多Level(\(Level_0, Level_1, \cdots, Level_N\)等),\(Level_0\)是原始Flush的数据,每一个文件对应一个MemTable,因此在\(Level_0\)中每一个Shard file可能包含非常多key,Shard file之间的key是重合的。
- \(Level_1\)是将\(Level_0\)的数据分成\(K\)份,开始对内容进行Compaction,除了将相同key的Record合并之外,还会继续保证下层的key是排序的,并且按照LSN从大到小排序,这么做的好处是根据\(LSN_{read}\)进行扫描的时候能够尽可能扫描少的数据,因此在\(Level_1\)中,每一个Shard file之间的key没有overlap。
- 但光有\(Level_1\)是不够的,因为有可能\(max\{LSN_{read}\}\)比\(max\{LSN_{write}\}\)小,此时有部分的Record需要保存全量而不能被Merged(因为一致性要求),所以\(Level_1\)仍然可能有冗余的Record存在,此时再Compaction出\(Level_2\)目的稍有改变,是为了减小\(Level_1\)中的Data block的大小,把LSN较大的Record继续放在\(Level_1\),LSN较小的Record放到\(Level_2\),这样需要扫描Data block的时候,保证读取的Block尽可能小,只是有需要的时候才去\(Level_2\)扫描更大的Block。
- 文中的描述是:当\(Level_i\)存储满后,会触发\(Level_i\)向\(Level_{i+1}\)的Compaction。
5.4 Hierarchical Cache(自底向上)
- Local disk cache:在SSD有一层缓存;
- Block cache(In-memory):在Tablet有一层缓存,记录频繁从Shard file读出来的Data block;
- Row cache(In-memory):在Tablet还有一层缓存,记录Data block merge后的数据。
6. 执行引擎
论文中对Execution Context的描述已经较为精简,因此本文不再赘述,需要了解细节的话直接看原文即可。
6.1 总览
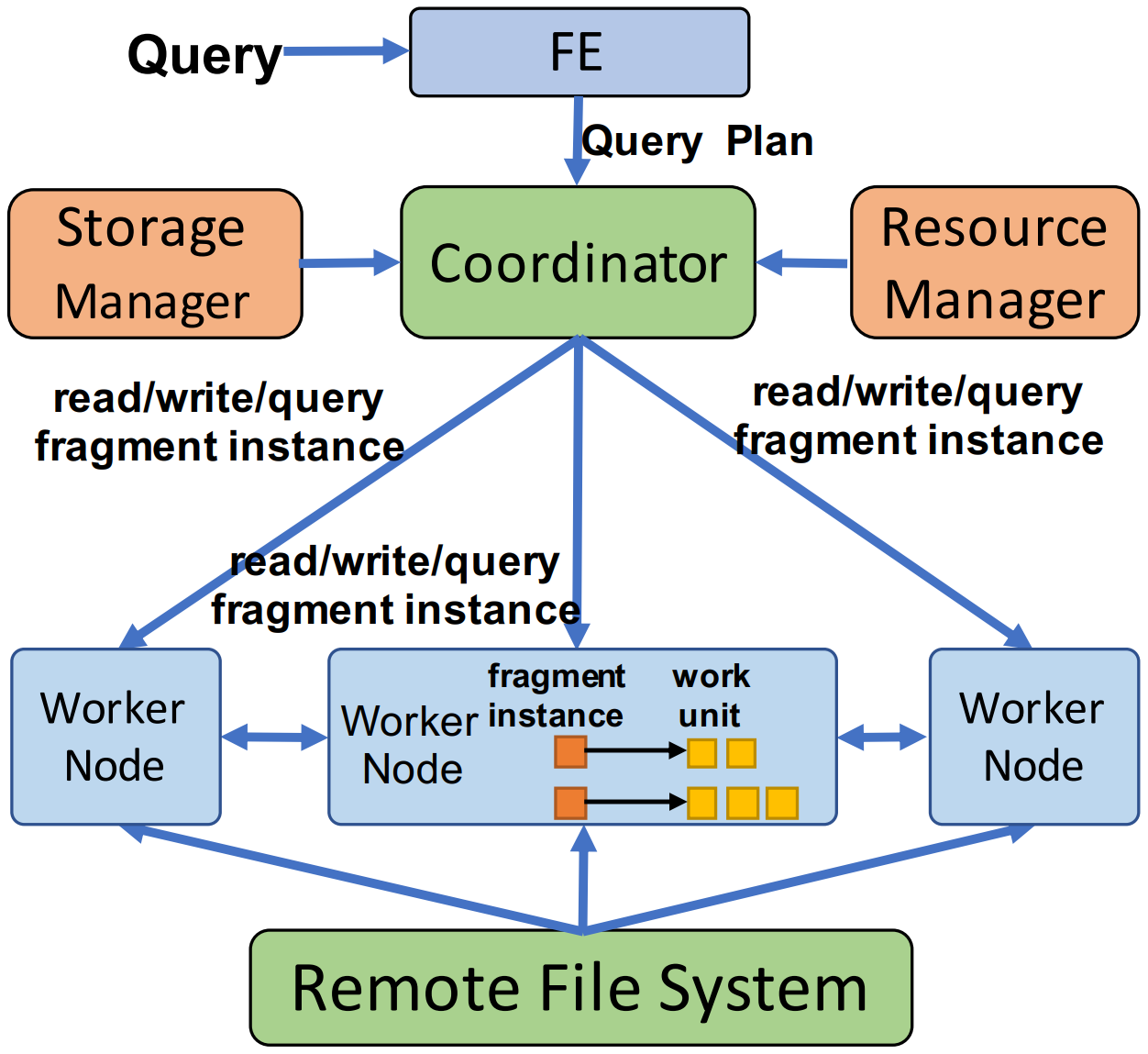
- FE接收Query后在FE节点的Optimizer会产生Plan,Plan的形式为由Fragment组成的DAG。
- Fragment有三种类型,Read/Write/Query fragment,其中Read/Write对应一个Table的读写操作,Query fragment负责其他操作。为了并行性,Fragment被进一步拆分成Fragment instances,每一个Fragment instances处理一个TGS。
- FE会把生成的DAG发送给Coordinator,由它将DAG中的Fragment instances分配(dispatch)给Worker Node,包含Read/Write的Fragment instances会被分配给对应TGSs的Worker Node;包含Query fragment instances会被分配给任意Worker Node,但会考虑Workload进行负载均衡。
- Worker Node收到Fragment instances后,会将他们映射到Work Units(WUs)中,WUs是Holo执行的基本单位,WU可以产生(spawn)WU。
6.2 Execution Context
- Holo提出一种用户空间的线程称为EC,作为WU的资源抽象。
- EC是协同调度的,需不要使用系统调度或同步原语,因此EC的Context switch开销几乎忽略不计。