A Brief Investigation to the HA of Mainstream MPP Database System
数据仓库领域能选择的产品非常丰富,闭源的有 Google BigQuery / Amazon Redshift / Azure Synapse Analytics 和 Snowflake 等;开源的有 Apache Doris / Apache HBase / ClickHouse / StarRocks 和 SelectDB 等。 既然是数仓,那么必然是大规模的数据量,那么肯定离不开 MPP 架构,那么也就多多少少得和云原生(cloud-native)打交道。即使一些开源项目刚开始和云原生没关系,但上了云厂商的 EMR 提供服务后,云原生的特性也会被用户关注起来。
云原生的一大特性是高可用(HA,High Availability),一般表现在几个方面:
- 数据高可用:冗余备份
- 集群高可用:故障恢复、负载均衡、资源隔离
- 弹性扩缩容:对服务是否有损
本文简要介绍几个数仓产品的后两个方面。
Apache Doris & StarRocks (SR)
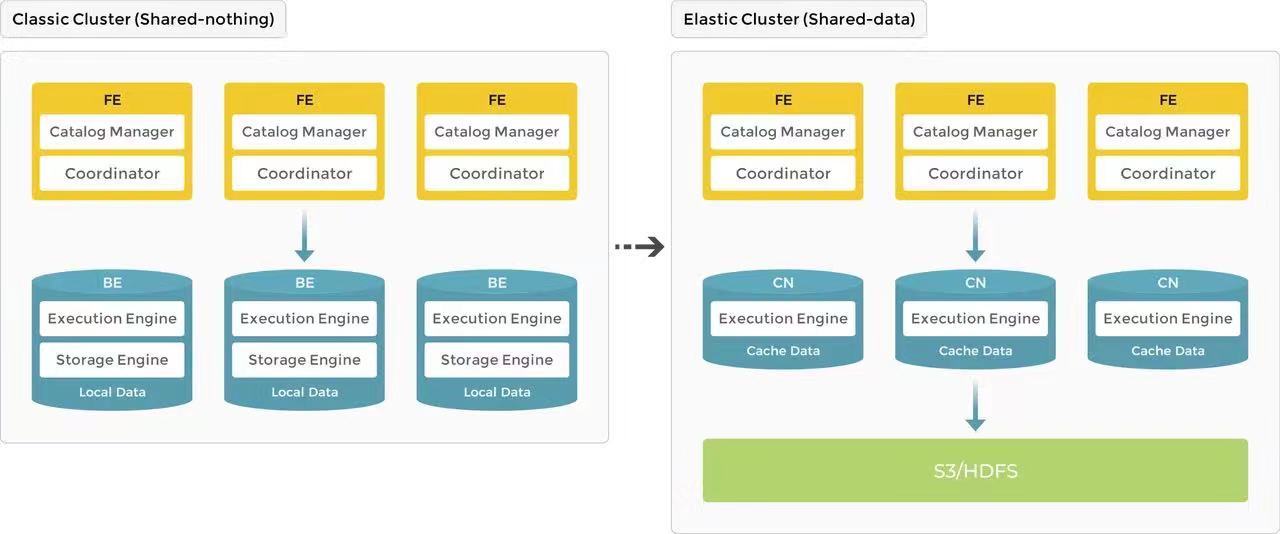
SR 3.0 架构(图源自参考)
既然 SR 是基于 Doris,这里就把它们放在一起讲,Doris 有的东西 SR 自然少不了。
架构上,Doris 只有 FE 与 BE 两种节点,FE 接收和处理 Query,BE 负责存储和计算;存储上,Doris 是 Shared-nothing 的设计,数据模型中最小单元是 Tablet,可以理解为一张表的数据分片,存储在不同的 BE 节点上。 Tablet 支持多副本形式,默认为三副本,以 Quorum 协议进行数据同步。 默认的三副本形式保证了数据的可靠和服务的高可用,只要 Tablet 的三副本保证不会部署到同一台机器上,故障恢复和弹性扩缩容理论上能做到无损。如果 BE 发生 Failover 那么还有另外两个副本;如果机器发生 Failover 那么一个 Tablet 同样是最多挂一个副本。而新增 BE 节点后对 Tablet 进行均衡,依靠 Quorum 协议也能做到无损。
Doris 有 TabletScheduler 模块来做 Tablet 的迁移和调度。有几种情况需要它干活:1. Tablet 副本不健康了,要重拉个新的;2. BE 负载重了,需要把 Tablet 迁移走一些。因此 TabletScheduler 和负载均衡息息相关。Tablet 健康程度由常驻的后台进程 TabletChecker 定期检查,BE 的负载用 ClusterLoadStatistics (CLS) 表示,具体怎么计算可以看 SR 文档。根据官方文档的描述,Doris 和 SR 的扩缩容易用性也很好,扩容后 TabletScheduler 会自动做均衡,缩容也会保证 Tablet 副本补齐再删除 BE 节点,理论上两个过程都无损。但有个小细节文档没说,下掉 BE 的瞬间仍在 Scan 老副本的 Long query 会不会报错,个人感觉应该不会,因为三副本的存在,理论上(或者说可以做到)会找其他副本重试。 有趣的事情是,这些内容应该是 Doris 就有的能力,但是 SR 的官方文档对它们描述更多。我觉得这是商业化带来的影响吧,虽然都是开源,但为了让用户更快上手和理解,文档中不得不对技术细节进行更多的描述。
Doris 和 SR 在故障恢复、负载均衡和扩缩容上的能力基本都是对齐的,但 SR 额外做了一些云原生化的改进。首先是计算存储分离的架构,SR 3.0 已经支持数据存储在 OSS 或 HDFS,意味着扩缩容能力会有提升。其次是 SR 的资源隔离用资源组(Resource group)概念完成,除了用户手动制定 Query 跑在哪个资源组外,资源组还可以搭配分类器使用,分类器用来判断 Query 分发给哪个资源组,例如:满足 user = ‘aaa’ 则分配给资源组 A,满足 db = ‘xyz’ 则分配给资源组 B,满足 query_type = ‘INSERT’ 则分配给资源组 C 等。我没有阅读源代码也没有试用 SR 产品,仅从官方文档中描述:
当资源组中运行的查询超过以上大查询限制时,查询将会终止,并返回错误。
推测 SR 的资源组超额判断是 Runtime 的,超额会使得正在运行的 Query 报错,也就是说资源组之间互不影响,但资源组内还是会打架。Doris 的资源隔离实践案例的资料很少,根据官方文档描述,它只能做到物理资源的强隔离,且只有读读隔离。
Apache HBase
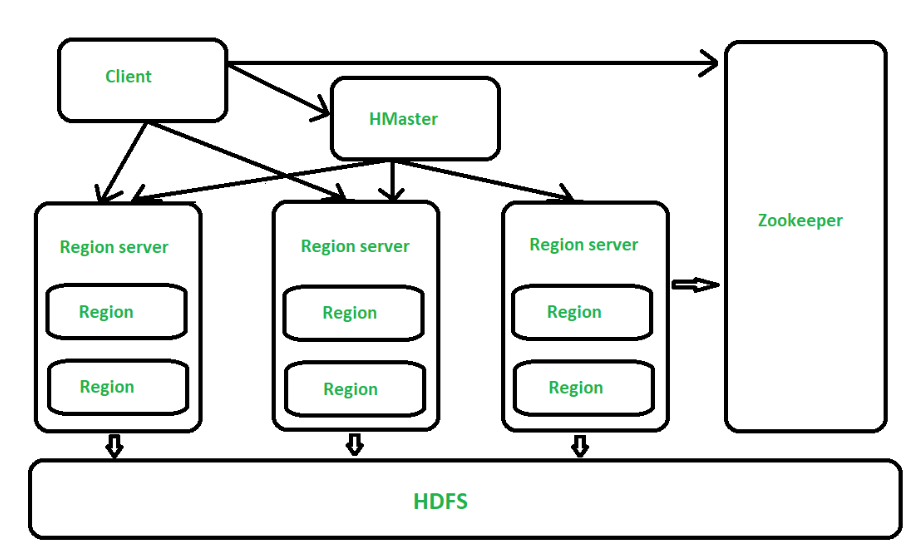
HBase 架构(图源自参考)
从架构的角度看 HBase 有三个角色:HMaster / Region Server / ZooKeeper。为了标识数据 HBase 提出 RowKey 的概念,从数据模型的角度看,它将 Table 划分为多个 Region,每个 Region 包含 RowKey 从 rk_start 到 rk_end 的数据。Region 可以理解为数据分片,存储在 Region Server 中,可以理解为计算节点,而底层存储为 HDFS,因此是存储计算分离的设计。回到架构中,HMaster 的职责是管理 Region(即数据)的,以及表的 Meta 信息、DDL 执行等等;ZooKeeper 是管理分布式调度和保证分布式节点一致性的。
HMaster 有多个副本,如果 HMaster 挂了,ZooKeeper 会快速从副本中选出最快恢复工作状态的 HMaster 作为主。HBase 也支持 Replica region(多副本),是以一主多从的形式来管理的,它能保证高可用的读能力,但是不能保证强一致性读,因为如果主挂了,从的数据同步肯定会受到影响,数据可能延迟,多副本的同步也不完全一致。同时写的高可用也不能保证,写入的恢复时间取决于主的恢复时间。由此可以看出一主多从的多副本形式缺点有:不保证强一致性读,不保证高可用写入。
HBase 的负载均衡同样是依靠 Region 在 Region Server 的均衡来保证。考虑迁移主 Region 的场景,迁移时数据同步不是问题,重点是主从切换的过程:HMaster 通过获取即将下线的 Region 的写锁来防止有新的写入,接着将即将上线的副本置为 Opening 状态(理解为标记 Region 服务 Ready),接着更新 ZooKeeper 和 HMaster 里的 Meta 信息,让新来的流量能找到该副本,最后将该副本置为 Open 状态(理解为标记 Region 可服务)完成迁移。整个过程是影响写入的,因此可以推测出 HBase 的弹性扩缩容肯定是有损的。
HBase 的资源隔离比较弱,只能做到 Region Server 隔离,即强物理隔离。由于主从多副本的存在,理论上可以做到高程度的资源隔离,只要主和从不在同一个 Region Server 并且支持指定流量打到副本上即可,但 HBase 对此支持貌似不好,没有搜索到相关实践案例。
Reference
StarRocks Docs
StarRocks 3.0 Zhihu
HBase Docs
Architecture of HBase