A bug of excessive memory usage (Related with Python GC and NumPy)
1. 前言
前段时间跑代码的时候发现我的程序占用大量内存,感觉十分不正常,在进行一系列的测试后终于找到原因所在。本文将Bug出现的场景简化、再现,并分析形成原因,给出解决方案。
2. 预备知识
2.1 Python垃圾回收机制(GC)
Python的垃圾回收机制有三种:
- 引用计数
- 标记清除
- 分代回收
它们的具体功能和做法不在此详细描述,可以查阅官方文档或其他资料了解。其中,“引用计数”是大部分工程师常接触到的,每个对象都维护一个引用数量,当引用数量为0时,说明该对象已经可以被释放了。
2.2 引用传递与值传递
Python的所有传递都为引用传递,网上很多总结会提到可变变量(List)和不可变变量(基本类型、tuple)的传递的区别,但结论仍然是:所有传递都是引用传递。
对此感兴趣的可以阅读文章:Which is Better in C++? Call by Value, Reference or Pointer
2.3 memory_profiler模块
This is a python module for monitoring memory consumption of a process as well as line-by-line analysis of memory consumption for python programs.
这是一个可以简单检查Python代码内存使用情况的模块,对于如何使用可以查阅官方文档。
3. 代码功能简介
实际的工程代码比较复杂,以下功能都已经过简化:
3.1 简介
-
对于一组数据(假设有500个数据),以图片为例(图片大小为\(32 \times 32 \times 3\)),那么数据总体的\(Size\)为:\(500 \times 32 \times 32 \times 3\);
-
每次随机从中选取一张图片(不重复),存到一个数组中;
3.2 实现
def func():
data = np.random.randn(500, 32, 32, 3).tolist() # List
selected = [] # List
for _ in range(100):
i = np.random.randint(low=0, high=len(data))
selected.append(data[i])
del data[i] # Remove it to avoid duplicative selection
以上是非常简单的实现,数据使用Python自带的List存储,最终也将数据存储到List中。
4. 内存占用测试
4.1 采用List存储
使用3.2中的代码进行测试,结果如下:
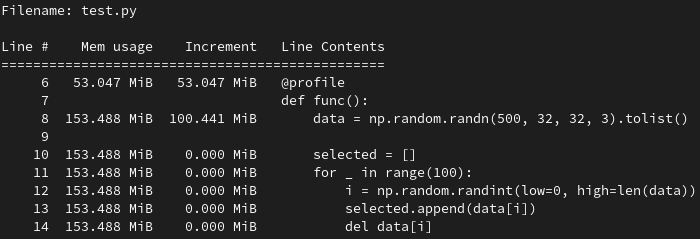
可见,内存占用量属于正常水平。
4.2 采用NumPy存储
代码变更为:
def func():
data = np.random.randn(500, 32, 32, 3) # NumPy array
selected = np.empty((0, 32, 32, 3)) # NumPy array
for _ in range(100):
i = np.random.randint(low=0, high=len(data))
selected = np.concatenate((selected, np.expand_dims(data[i], axis=0)))
data = np.delete(data, i, axis=0) # Remove it to avoid duplicative selection
输入的数据由NumPy存储,选择出的数据也是由NumPy存储,测试结果如下:
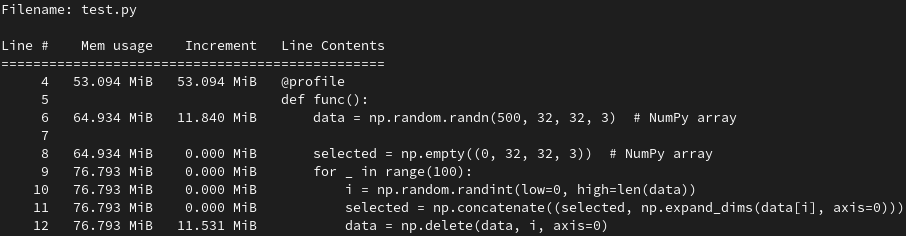
使用NumPy数组存储后,内存占用缩减一半,NumPy的优化果然不让人失望!
4.3 混合存储
当时写这段代码的时候我疏于考虑,传入的数据是NumPy数组,用List去存储选择的数据,产生了一些问题,代码如下:
def func():
data = np.random.randn(500, 32, 32, 3) # NumPy array
selected = [] # List
for _ in range(100):
i = np.random.randint(low=0, high=len(data))
selected.append(data[i])
data = np.delete(data, i, axis=0) # Remove it to avoid duplicative selection
当NumPy和List混合在一起使用时,要格外注意,以上就是一个例子。当时写完后整个程序的功能没有问题,所以后续没有仔细检查,导致没有发现问题。
内存占用测试如下:
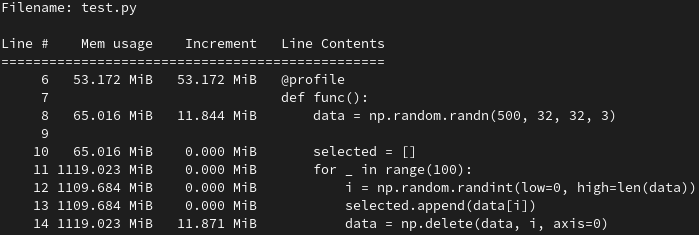
结果令我震惊,为什么突然会占用这么多内存?
5. 问题分析
5.1 原因
-
np.delete函数会复制一份新的数组,从三个现象可以看出:
1) 函数有返回值,而不是直接对数组进行操作;
>>> import numpy as np >>> a = [1, 2, 3] >>> b = np.delete(a, 1, axis=0) >>> a [1, 2, 3] >>> b array([1, 3]) >>>2) \(4.2\)和\(4.3\)的内存占用测试结果中,最后一行(np.delete)都有\(11\)MiB的内存Increment,for循环一共执行100次,\(11MiB*100 = 1100MiB\);
3) 看NumPy源码的np.delete部分。
-
复制了新的数组后,按正常流程,原先的对象应该要被Python的GC回收掉,释放内存。但是由于之前使用了List.append函数,根据\(2.2\),Python的参数传递都是引用传递,此时List中存储了对NumPy数组某个元素的引用,所以引用计数不为0,所以GC无法回收旧的NumPy数组。
-
由于旧的NumPy数组一直无法回收,内存无法释放,所以随着循环进行内存不断叠加,导致占用大量内存。
5.2 解决方案
-
最好的解决方案是统一使用NumPy或List(能用NumPy是最好的,无论对于内存占用还是CPU资源消耗都经过优化),但很多情况也避免不了混用;
-
List中每次append数据时,都使用tolist()转成List形式(selected.append(data[i].tolist()));
-
List中每次append数据时,都用np.array()转成新对象(selected.append(np.array(data[i])));
-
… (如果了解了原理,修这个小BUG应该有各种各样的方法了)
5.3 其他问题
Q: 为什么使用List存储时,采用del方法不会导致内存占用增加?
A: 因为在Python的List实现中,移除某个值的功能是不会复制新数组的,而是在原本的数据上进行操作,时间复杂度为\(O(n)\)。
>>> a = [1, 2, 3]
>>> id(a)
140312938701888
>>> del a[1]
>>> a
[1, 3]
>>> id(a)
140312938701888
>>>
6. 总结
NumPy真是一个伟大的项目,它已经成为Python处理数据的标配,能用NumPy就尽量用。我们在写代码的时候经常忽略许多编程语言特性的细节,小则导致占用多一些的内存,大则可能产生安全问题,但没有人能写出完美的代码,只能做到尽可能规范和细心。最后,非常感谢@lonelyenvoy的分析和帮助。